Web cache poisoning has long been an elusive vulnerability, a 'theoretical' threat used mostly to scare developers into obediently patching issues that nobody could actually exploit.
We can see how to compromise websites by using esoteric web features to turn their caches into exploit delivery systems, targeting everyone that makes the mistake of visiting their homepage.
Core Concepts
Caching 101
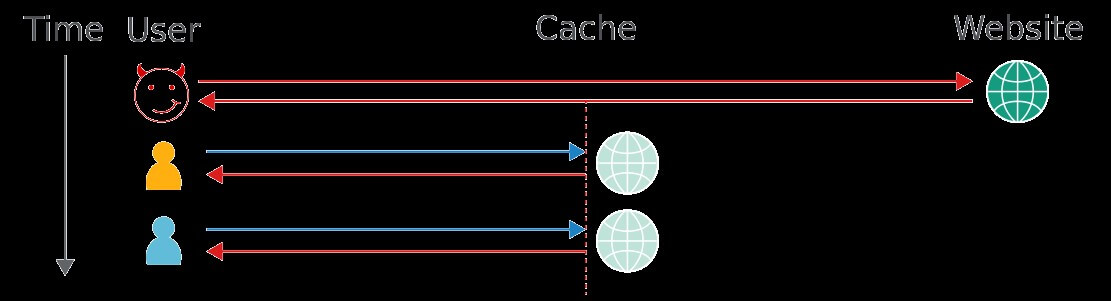
To grasp cache poisoning, we'll need to take a quick look at the fundamentals of caching. Web caches sit between the user and the application server, where they save and serve copies of certain responses. In the diagram below, we can see three users fetching the same resource one after the other:
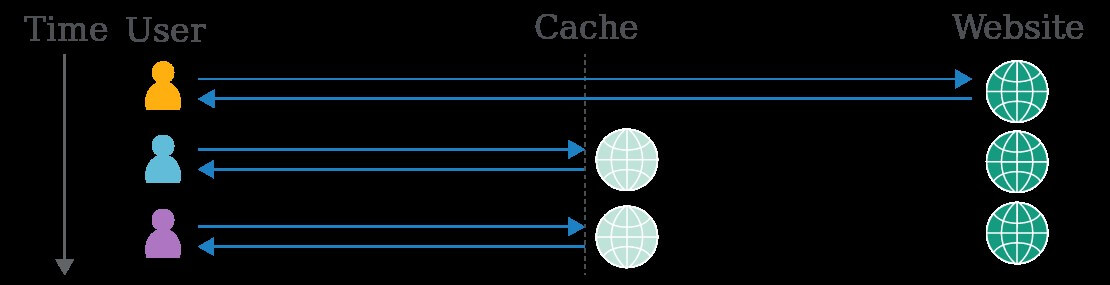
Caching is intended to speed up page loads by reducing latency, and also reduce load on the application server. Some companies host their own cache using software like Varnish, and others opt to rely on a Content Delivery Network (CDN) like Cloudflare, with caches scattered across geographical locations. Also, some popular web applications and frameworks like Drupal have a built-in cache.
There are also other types of cache, such as client-side browser caches and DNS caches, but they're not the focus of this research.
Cache keys
The concept of caching might sound clean and simple, but it hides some risky assumptions. Whenever a cache receives a request for a resource, it needs to decide whether it has a copy of this exact resource already saved and can reply with that, or if it needs to forward the request to the application server.
Identifying whether two requests are trying to load the same resource can be tricky; requiring that the requests match byte-for-byte is utterly ineffective, as HTTP requests are full of inconsequential data, such as the requester's browser:
GET /blog/post.php?mobile=1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 … Firefox/57.0
Accept: */*; q=0.01
Accept-Language: en-US,en;q=0.5
Accept-Encoding: gzip, deflate
Referer: https://google.com/
Cookie: jessionid=xyz;
Connection: close
Caches tackle this problem using the concept of cache keys – a few specific components of a HTTP request that are taken to fully identify the resources being requested. In the request above, I’ve highlighted the values included in a typical cache key in red.
This means that caches think the following two requests are equivalent, and will happily respond to the second request with a response cached from the first:
GET /blog/post.php?mobile=1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 … Firefox/57.0
Cookie: language=pl;
Connection: close
GET /blog/post.php?mobile=1 HTTP/1.1
Host: example.com
User-Agent: Mozilla/5.0 … Firefox/57.0
Cookie: language=en;
Connection: close
As a result, the page will be served in the wrong language to the second visitor. This hints at the problem – any difference in the response triggered by an unkeyed input may be stored and served to other users. In theory, sites can use the 'Vary' response header to specify additional request headers that should be keyed. in practice, the Vary header is only used in a rudimentary way, CDNs like Cloudflare ignore it outright, and people don't even realise their application supports any header-based input.
This causes a healthy number of accidental breakages, but the fun really starts when someone intentionally sets out to exploit it.
Cache Poisoning
The objective of web cache poisoning is to send a request that causes a harmful response that gets saved in the cache and served to other users.
This isn't the only way of poisoning caches - you can also use HTTP Response Splitting and Request Smuggling - but it is the most reliable. Please note that web caches also enable a different type of attack called Web Cache Deception which should not be confused with cache poisoning.
Methodology
We'll use the following methodology to find cache poisoning vulnerabilities:
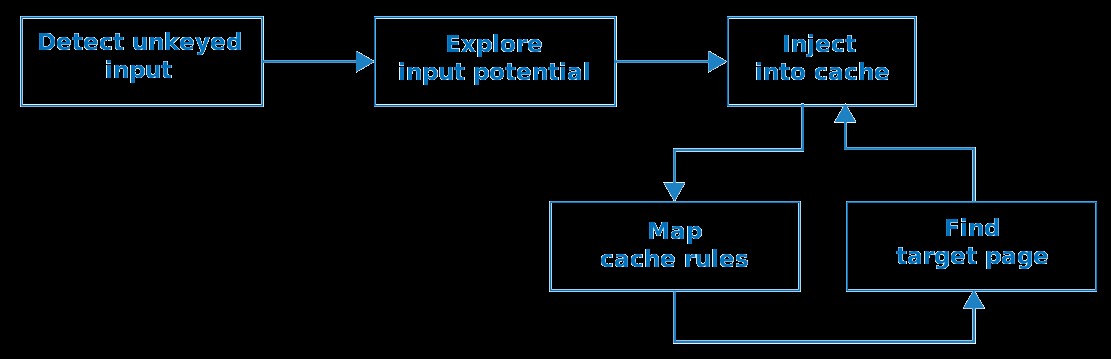
Rather than attempt to explain this in depth upfront, I'll give a quick overview on how it is being applied to real websites.
The first step is to identify unkeyed inputs. Doing this manually is tedious so we can use an open source Burp Suite extension called Param Miner that automates this step by guessing header/cookie names, and observing whether they have an effect on the application's response.
After finding an unkeyed input, the next steps are to assess how much damage you can do with it, then try and get it stored in the cache. If that fails, you'll need to gain a better understanding of how the cache works and hunt down a cacheable target page before retrying. Whether a page gets cached may be based on a variety of factors including the file extension, content-type, route, status code, and response headers.
Cached responses can mask unkeyed inputs, so if you're trying to manually detect or explore unkeyed inputs, a cache-buster is crucial. If you have Param Miner loaded, you can ensure every request has a unique cache key by adding a parameter with a value of $randomplz to the query string.
When auditing a live website, accidentally poisoning other visitors is a perpetual hazard. Param Miner mitigates this by adding a cache buster to all outbound requests from Burp. This cache buster has a fixed value so you can observe caching behaviour yourself without it affecting other users.